
Virtual Reports Suites (VRS) have revolutionized the way organizations think about many aspects of Adobe Analytics implementations. Starting with data collection, they have offered a fresh alternative to multi-suite tagging. By introducing the concept of Report Time Processing, they've unlocked valuable new configuration/reporting capabilities. Layering segmentation, element curation, and report suite-level access permissions has paved a flexible new way to meet challenges in data dissemination.
In a nutshell, Virtual Report Suites allow you take a regular report suite, apply a number of configurations and segments, and carefully curate the reporting elements you wish to display to end users. This combination of features make Virtual Report Suites a powerful resource for addressing data quality issues.
The use cases we’ll discuss in this blog post revolve around the following key moments:
- A data quality issue is diagnosed.
- The issue can be isolated through a combination of techniques: segmentation, classification, custom metric creation, element curation.
- A Virtual Report Suite is created or updated to remedy the underlying data quality issue or mitigate its impact to the audience.
The Basics: Segmentation
Your company opened a new office and fellow employees from the new office location generated a lot of activity on your website. It took a couple of days for someone to notice and for the new office IP's to be excluded from Adobe’s reports, but the activity that was recorded in you report suite for the days in question is now skewing conversion rates, wreaking havoc to your Marketing Channels reporting, and inflating various KPI's.
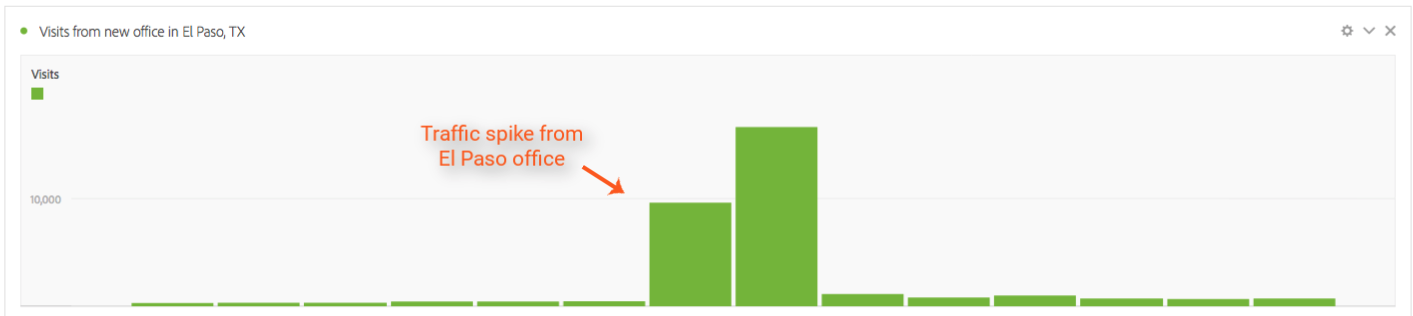
With Virtual Report Suites this can be addressed by creating a segment that excludes this traffic. If you are already passing the visitor IP to a prop or an eVar, the segment could be based on such dimensions or you can construct your segment logic off of built-in dimensions such as City or Domain.

Incorporating the new segment to your virtual report suite will retroactively adjust all data for the affected days in question and your end users will no longer need to account for the unexpected spike in traffic:

If It Looks Like a Spider And It Moves Like a Spider…
Robotic activity will also inflate the data you collect in Adobe. Such activity can be difficult to pinpoint—if you are lucky spider hits are clustered around a set of IP's that you can segment out using the technique we discussed earlier. However, in some cases the activity can be spread out across many IP's, the user agent strings may have been carefully modified to mimic actual devices/browsers, and the detection of spiders may prove much trickier.
In some cases a good alternative to try to detect such traffic is to use the client side attributes that are normally collected by the tracking JavaScript (Java Enabled, Color Depth, etc…). In many spider implementations these properties may not get set or there would be giveaways—suspiciously small browser heights or widths for example. Outdated browser versions hard-coded in spider implementations can also provide you with clues. Careful examination of these dimensions and combining them in a segment may prove a valuable addition to your VRS segments.
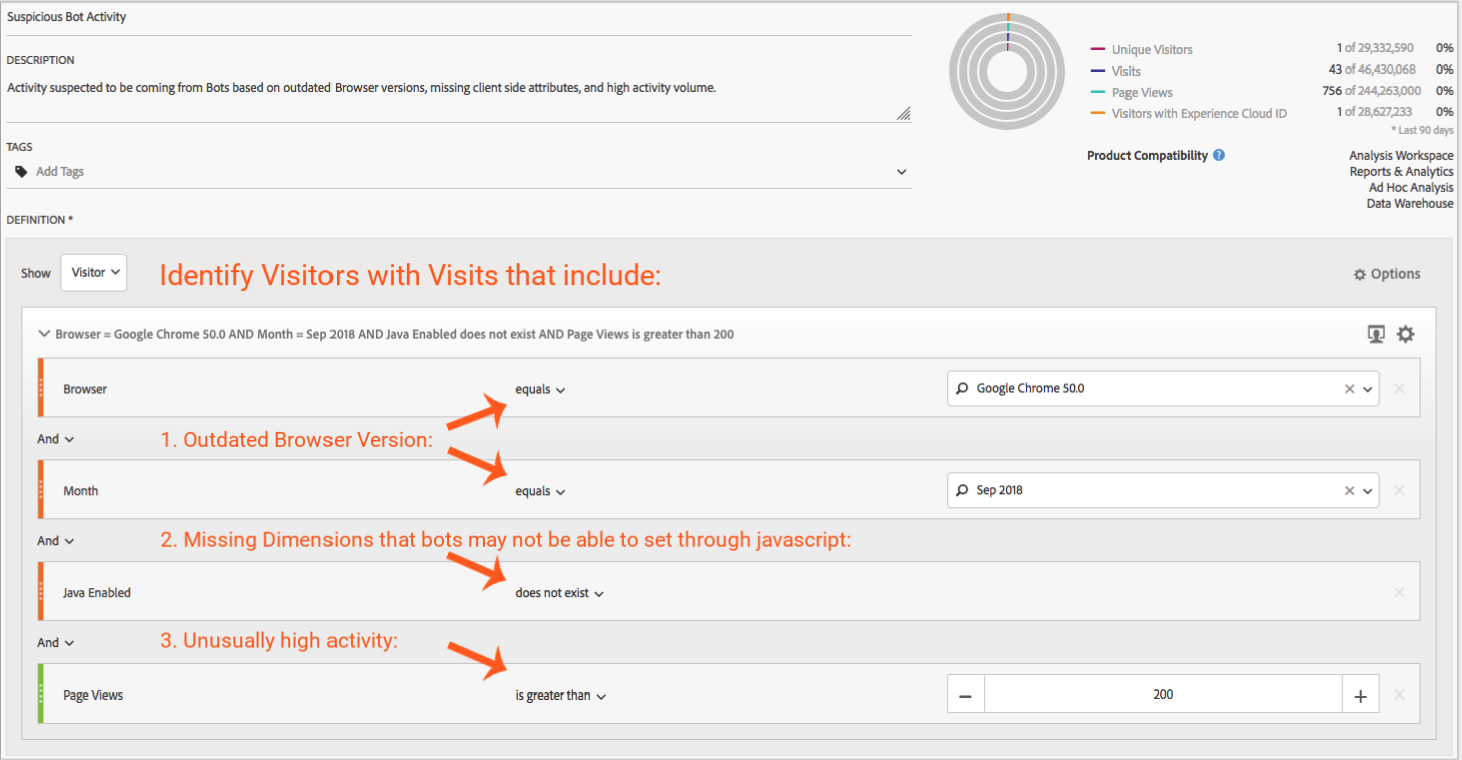
Another alternative might be to create a segment that excludes Visitors or Visits with more than n instances of a particular metric. The n is a somewhat arbitrary number you decide makes sense based on the traffic patterns you notice. Adobe has also released a JavaScript plugin that is not too dissimilar in the approach it takes to flagging such activity.
Tags Were Dropped… Again
Things happen to tags. No matter how robust the implementation, a seemingly endless supply of predators can crush or maim them.
One of the most common (and easiest to identify) patterns is when a particular tag disappears altogether. Any metric or dimension value dependent on the extinct tag will flatline immediately.
After inspecting the page or action sequence, you discover that indeed the tag is gone. The news can be pretty devastating. There is now a gaping hole in your reporting and it not only prevents you from reporting on the KPI in question, it will also haunt DoD, WoW, MoM and any custom date range comparisons.
Because such occurrences are common, analysts have come up with plenty of creative ways to minimize their impact. One technique is estimation—if the metric you are missing is closely correlated to another, presumably intact, data point, you can leverage the power of Calculated Metrics to estimate the missing values. In the process, you end up creating a new calculated metric that acts as proxy for the real metric. You can now generate the reporting you need using this substitute metric, but having multiple metrics that seem to report the same thing can be quite confusing. In a large organization with multiple analysts using the data, it can be a gateway to chaos.
This is where curation capabilities made available by Virtual Report Suites can come in handy. Not only are you able to "hide" impacted metrics from the end users, you can rename calculated / substitute metrics to match the names of the original metrics, presenting analysts with a much cleaner set of reports:

Painting Over the Ugly Bits, with Classification
Classification in Adobe is another valuable feature. It lets you add meta data about the various data points you collect and translate cryptic strings into meaningful, business-friendly names. In the process, it unlocks powerful new reporting capabilities.
SAINT or rule-based classification techniques have also been used to fix pesky mistakes that often result in rogue values leaking into your dimensions. Think of seemingly trivial items such as typos and spelling mistakes, extra spaces, or punctuation variations that can demolish the cosmetics of your beautiful implementation. A prime example are campaign ID's. How often do you see multiple strings that are supposed to represent the same campaign code? Such ugliness can be “fixed” with classification, but the underlying dimension (with the pesky deviations) will continue to persist in regular report suites and it may be difficult to keep it away from the eyes of your audience. Enter VRS.
The curation component of Virtual Report Suites provides you with the needed flexibility to decide which dimensions you present to the end user, allowing you to hide "messy" dimensions and display a curated version to the group of users that will have access to the resulting meta-suite.
Another often-used approach in implementations are eVar values that have been "overloaded" to include more than just one attribute. The resulting raw eVar usually displays a long concatenated string that is borderline unreadable, so having the option to hide it is another welcome boon of using VRS.
Enjoy Responsibly
Virtual Report Suites are not a magic bullet and they are no substitute for proper diagnosing and correction of data quality issues, which is the best and only recommended goal. However, with solid communication in place, VRS can be a valuable arrow in the quiver to help mitigate the impact of data quality gaps.
About Us
QA2L is a cloud-based tag auditing platform that allows automation of tests across key site flows. QA2L's technology enables the recording, replay, and editing of complex interactions across any highly dynamic site of the modern web.
Request a Demo
Tags: Data Quality Adobe