Confluence and Self-Documenting Tag Audits
The pain points of creating and maintaining tagging specifications have been discussed before. But documenting the results of tag checks/audits is a topic of its own merit. What scenarios require organizations to document tag validation? What are the various approaches, their benefits and drawbacks? Where do organizations fall short most often, and what are some exciting new capabilities that can help put everyone on the same page?
Why Are Tag Audits Necessary?
The primary use case for documenting tag audits is when an organization is in the process of first implementing a tracking framework on a new site or native app. Large organizations in particular usually have different resources to handle the tag placement (developer team) vs. the tag validation (web analytics team). Sometimes, there are multiple stakeholders on the tag validation side, for example an agency that is responsible for the final reporting. Naturally, the different teams need to document the process and communicate clearly across, even outside, the organization.
Another common use case for documenting tag audits is of course related to the discovery of tracking defects and reporting anomalies. If you are lucky, these defects are as straightforward as beacons not firing on page load and causing a flat line in dimensions or metrics. But in reality, you're almost never that lucky. Any reasonably sophisticated tracking implementation is open to issues that are much harder to diagnose, ones that lead to subtle data quality degradation that may take weeks, even months, to discover.
An organization that is further along in analytics maturity might have tagging audits produced regularly or triggered at the time when new code makes its way from lower environments into production. Tag verification is an integral part of the company's analytics operations and one of the key aspects of the job that need to be communicated when training /onboarding new team members.
How are Tagging Checks Documented?
It's the Wild West out there and there is no sugarcoating it. There's no standard, no prevailing best practice. Depending on the preferences of the process owner or the organization as a whole, tag audits might be recorded in spreadsheets, raw dumps of intercepted HTTP requests may reside inside email threads and file attachments, individual tracking parameters might be sent to developers in chat windows or Slack messages, awkwardly captured in Powerpoint slides, described verbally in bug tracking systems, walled inside the environments of third-party vendors, or stored in home-grown databases.
It is rarely the case that organizations have the bandwidth and the tools to approach this in a systematic way. In many cases, the records of even the most basic tagging audits (such as prior to a major release) are not event available for back-reference. Or if they are available, they are scattered and lack any consistency. With the average tenure of an analytics professional reported at 18 months, is it any wonder that analytics platforms periodically fall out of favor, to be substituted with the latest fashionable tool, only for it to fall victim of the same endemic issues?
Looking ahead with Confluence and Self-Documenting Tag Audits
Atlassian Confluence is used by many organizations, providing team members shared collaboration workspaces for the documentation of various projects. A wealth of features make this platform a natural destination for the ongoing storage of tag audits:
- Ability to curate and collaborate on individual pages with flexible user permissions.
- Ability to attach / embed external resources.
- Deep integration with the popular Atlassian JIRA issue tracker.
- Notifications of team members.
- Content version control.
Organizations can structure Confluence pages to lay out and document valuable information describing the data collection phase of analytics operations:
- Documenting key user workflows with screenshots for each of the steps.
- Stating the expected tracking parameters enabling quality data collection for each of the steps.
- Sharing the actual tracking parameters observed at the time of a validation pass.
Automating Confluence Tag Audits with QA2L
QA2L's validation platform can fully automate the process of posting tag audit results to Confluence. The setup is simple and can help your organization develop an ongoing, self-updating repository for all of your most important data quality checks.
By turning your ad hoc and automated validation tasks into Confluence pages, you can create a space where multiple teams coordinate actions on data collection defects. This helps ensure the quality of data not only at the time when new tracking is added but also when continuous changes to web properties undermine collection integrity.
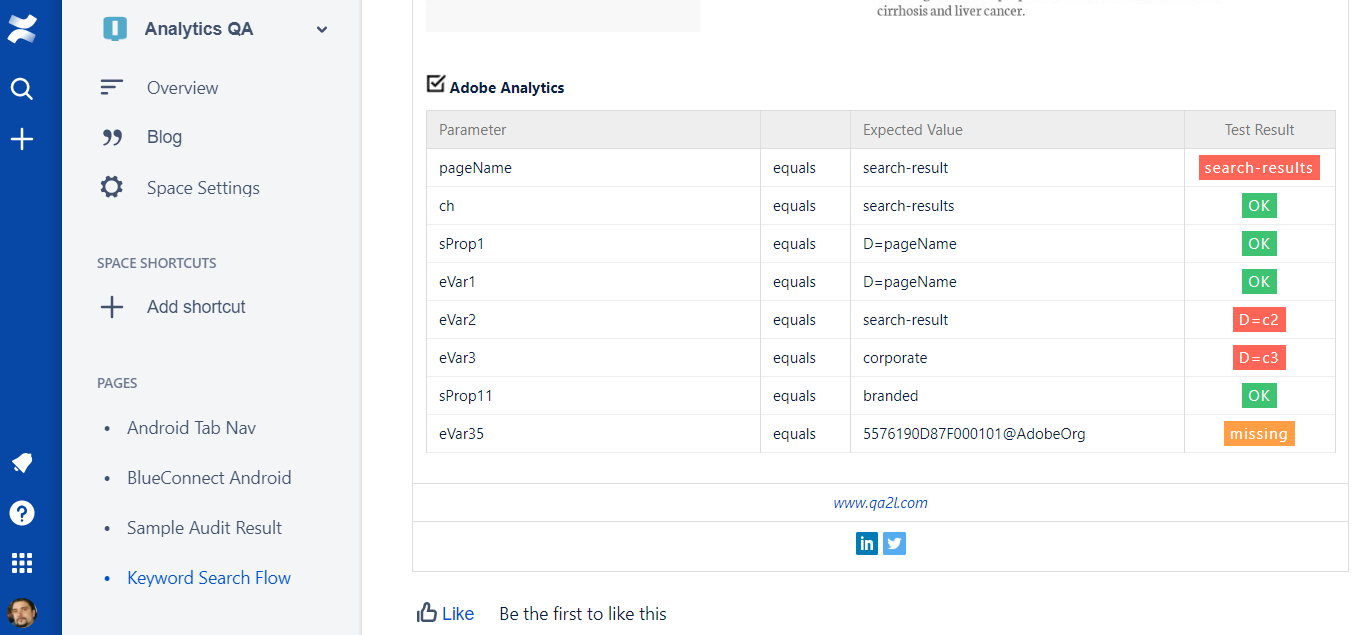
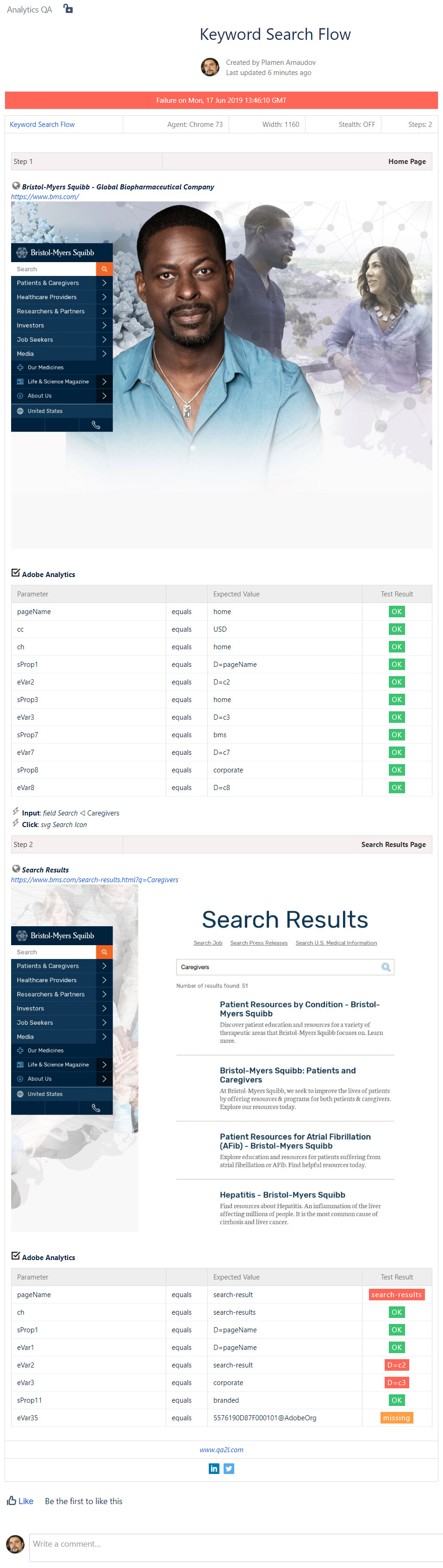
Below is an example of a two-step keyword search flow along with the expected Adobe Analytics parameters and the actual test results.
If you are interested in learning more, contact us to schedule a personalized demo.
Tags: Data Governance Product News