Adobe Experience Platform and Alloy.js ushers a new approach to data collection, turns a page on tag validation
by Nikolay Gradinarov
One of the highlights of Adobe’s virtual Summit 2020 is a brand new method for data collection dubbed “Alloy.js”.
The session "Data & Insight: Gaining True Customer Intelligence" featuring Eric Matisoff, along with the session "Meet Alloy.js and Never Tag for an eVar or Mbox Again" co-presented by Corey Spencer and Brandon Pack, reveals some of the features of Alloy.js:
- A unified, lighter JavaScript library using a single type of request to collect data across products. This is a big step forward and away from the existing methods of client-side data collection requiring multiple JS libraries (Analytics, Target, etc…) each with its own collection logic and request shape.
- An open and flexible event-based schema allowing the definition of any custom events/attributes to be appended to the tracking request. This is a logical continuation of the open schema data layer design, allowing the abstraction of tracking events and attributes from the Adobe-specific syntax of eVars, s.props, s.events, etc.
- A first-party Edge destination for the unified beacons. While there are some CNAME implementations for existing Adobe services, a large number of Adobe Analytics tagged websites send to omtrdc.net or the legacy 112.2o7.net domain. For them, any first-party cookies generated by Adobe’s scripts have relied on JavaScript document.cookie, leaving them more exposed to new privacy rules implemented by various browsers.
- The Edge Network is capable of streaming the data to multiple applications server-side. This makes it possible for many different marketing-technology applications both in and outside the Adobe Experience Platform to piggyback on the information supplied by the Alloy beacon:
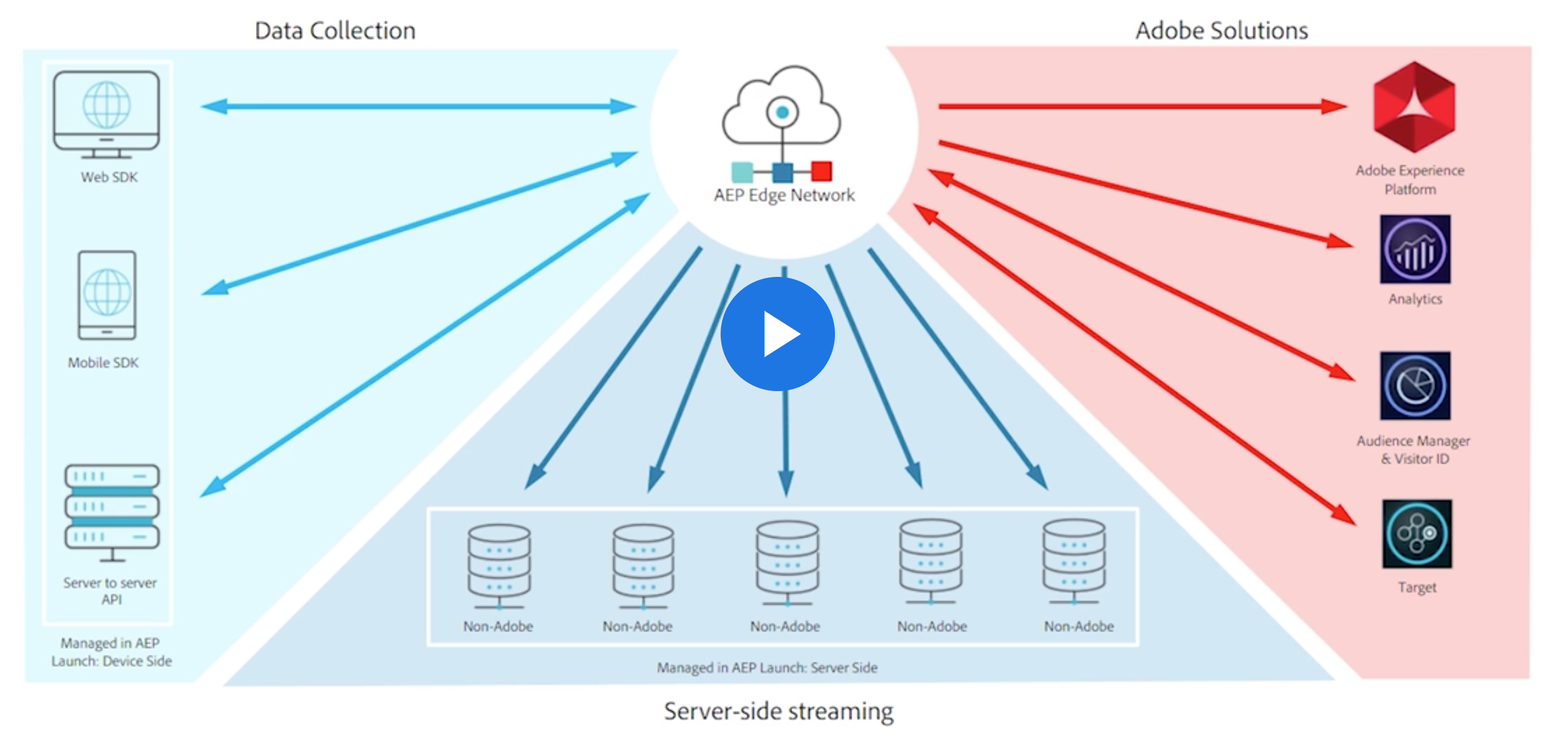
To sum up some of the more apparent benefits of this new approach:
- Improves page performance by loading a smaller tracking library.
- Improves the reliability of visitor identification through collection taking place in a first-party secure (non-JS) cookie context, thus bypassing growing browser restrictions.
- Makes the same visitor identifier (as well as all event/attribute data) universally and consistently available across different solutions.
- Minimizes the transmission of client-side data.
- Improves safeguards against privacy violations, with centralized controls over cross-platform data sharing.
What does this method of data collection mean from a data quality standpoint?
- Improved visitor identification - by virtue of switching to secure first-party server-side cookies from an Edge endpoint, returning users would be tracked more reliably.
- Shared visitor IDs across multiple marketing technologies make it possible to more easily and reliably join data from different data sources.
- Consistent data (events and event attributes) can be sent to different vendors. Server-side data distribution improves the reliability and consistency of data streams to different MarTech solutions. Historically, even in the best TMS-driven implementations, the data sent to multiple vendors differs not just in structure, but also due to client-side factors such as load times, internet connection speeds, batching of requests, etc.

It's a new (Alloy.js) day for data quality. image by geckzilla
Some less apparent implications for data quality:
- The tagline from Adobe is: "Say good-bye to eVars and Mboxes." Beneath this lies a more mature and modern way of thinking about organizing the way data is being collected. The event+event attribute(s) open schema (which by the way is something that the most recent Google Analytics Web + App data collection has also fully embraced) puts into focus the requirements of modern websites where many legacy concepts such as "Page Views", "Time on Site," and "Bounce Rate" are no longer relevant. The over-arching trend is for more and more implementations to start with a set of meaningful conversion events and their attributes. An open event schema should compel even more rigid organizations to start by identifying what’s important, discouraging further the status quo of "slapping on the generic script" and putting off the KPI discussion indefinitely.
- The QA of tags through the traditional means of inspecting network requests generated by the client is now often going to be limited to inspecting a single request. This could mean:
- A heightened focus on the single tracking request as "the single source of truth" and making sure that all of the parameters expected are issued at the right time, in the right context, in the correct quantity. Automated tag governance tools should be able to detect all attributes, validate the tagging rules, and faithfully execute test cases across key user flows. Tag validation technologies should easily support SPAs, complex user journeys (check out flows, form inputs, interactions with social logins, etc).
- Automated flow/journey-based validation of the data layer will continue to be important since its job is to ensure that the tracking request always meets expectations.
- Automated tag audits that claim to scan hundreds and thousands of pages to list out all tagging vendors will eventually become obsolete. Such reports were never a centerpiece of a mature tagging validation strategy, showing tables overflowing with endless minutia without telling a story or drawing a clear picture. With Alloy.js, this approach to data quality will look even more superficial than it does already.
- Visualizations such as tag sequencing and hierarchies have always been more of a marketing gimmick, often showing inaccurate information and not passing scrutiny under closer observation. Such artifacts will eventually become a thing of the past, given that the client side will only issue a single Alloy.js request which explodes into data feeds server-side.
We expect to learn more details from Adobe soon about Alloy.js (currently in alpha) and the methods for distributing feeds from the Edge server to various vendors. It would not be unexpected to learn that Adobe has validation middleware in mind as they consider the ways in which many of their existing enterprise clients seek and receive the assurance of automated tag validation.
May 2020 update: an overview of the data validation options for Adobe Alloy.
|
|
|
|
QA2L is a data governance platform specializing in the automated validation of tracking tags/pixels. We focus on making it easy to automate even the most complicated user journeys / flows and to QA all your KPIs in a robust set of tests that is a breeze to maintain.
|
|
Tags: Data Quality Adobe